Bài 9: Vấn đề răng cưa, hội tụ chậm của mô hình nhị phân và 3 cách khắc phục
Cùng tìm hiểu hai hạn chế "dao động răng cưa" và "tốc độ hội tụ chậm" của mô hình nhị phân. Khám phá ba giải pháp thực tiễn như Richardson Extrapolation triệt tiêu sai số bậc 1/n; Black-Scholes Smoothing làm mịn hiệu ứng răng cưa; và Leisen-Reimer (1996) thiết kế lại cấu trúc cây để tối ưu hiệu năng cũng như độ chính xác.
Trong các bài viết trước, chúng ta đã tìm hiểu lý thuyết về mô hình nhị phân, cách xây dựng, cách hiệu chuẩn và cách thực thi code để định giá quyền chọn. Bài viết này, tôi sẽ giới thiệu nhiều hơn về khía cạnh thực hành, một vài hạn chế của mô hình nhị phân cũng như cách khắc phục thực tế. Một số chủ đề sẽ được đề cập như sau:
- Hạn chế của mô hình nhị phân: Hiệu ứng răng cưa và tốc độ hội tụ chậm.
- Richardson Extrapolation (RE): Kỹ thuật đơn giản nhưng mạnh mẽ giúp đạt độ chính xác của cây 1000 bước chỉ bằng cây 100 bước.
- Black-Scholes Smoothing (BSS): Kỹ thuật làm mượt nhằm loại bỏ hiệu ứng răng cưa.
- Leisen-Reimer (1996): Cấu trúc cây nhị phân giúp tối ưu hiệu năng cũng như độ chính xác.
Trong bài viết này:
- 1. Hạn chế của mô hình nhị phân
- 2. Richardson Extrapolation: Giải pháp tăng tốc hội tụ
- 3. Black-Scholes Smoothing: Kỹ thuật làm mượt và ổn định sai số
- 4. Leisen-Reimer (1996): Cấu trúc cây nhị phân tối ưu
- 5. Tóm tắt và thảo luận
- Appendix
1. Hạn chế của mô hình nhị phân
1.1. Hiệu ứng răng cưa: Sự mất ổn định khi thay đổi số bước nhảy
Trong Bài 8, chúng ta đã hiểu vì sao định giá American Option lại cần đến cây nhị phân, một công cụ linh hoạt cho phép so sánh tại mỗi nút để đưa ra quyết định thực hiện sớm hay tiếp tục.
Tuy nhiên, nhớ lại trong Bài 7, chúng ta gặp phải một rào cản kỹ thuật khá khó chịu khi hiệu chuẩn mô hình, đó là hiệu ứng răng cưa (sawtooth effect). Hiện tượng này khiến giá quyền chọn không hội tụ mượt mà mà nhảy vọt thất thường khi số bước $n$ thay đổi, đặc biệt là khi giá thực hiện $K$ nằm chơi vơi giữa các nút của cây.
Hãy thử nghiệm lại định giá American Put bằng cây nhị phân CRR với các tham số như sau $S=100$, $K=100$, $T=1$, $r=5\%$, $\sigma=20\%$, nhưng thay đổi số bước $n$ từ 10 đến 200.

Kết quả nhận được không phải là một đường cong hội tụ mịn màng, thay vào đó là một đường gãy khúc trông như răng cưa (Hình 1). Với $n=100$ cho giá $6.082$, $n=101$ cho giá $6.105$, $n=102$ lại cho giá $6.083$. Giá cứ dao động xung quanh một giá trị trung tâm.
Trong thực tế, hiệu ứng răng cưa không chỉ là một vấn đề thẩm mỹ trên biểu đồ hội tụ, mà còn gây ra sai số lớn khi tính toán các chỉ số Greeks (delta, gamma, etc.) ảnh hưởng rất lớn tới việc phòng hộ của các nhà môi giới quyền chọn.
Các chỉ số Greeks về bản chất là đạo hàm, thể hiện mức độ thay đổi của giá quyền chọn trước biến động của các tham số đầu vào. Delta là đạo hàm bậc nhất, đo sự thay đổi của giá quyền chọn theo sự biến động của giá cổ phiếu cơ sở. Chỉ cần $S$ thay đổi một chút, vị trí tương đối của $K$ với các nút thay đổi, dẫn đến delta nhảy vọt một cách phi lý. Nếu Delta đã không ổn định, đạo hàm bậc hai là gamma sẽ hoàn toàn bị nhiễu và có thể xuất hiện những cú sốc cực lớn. Điều này khiến việc phòng hộ trở nên bất khả thi vì hệ thống sẽ yêu cầu trader mua/bán một lượng cổ phiếu khổng lồ.
1.2. Tốc độ hội tụ: Sự đánh đổi giữa độ chính xác và hiệu năng
Khi chúng ta xây dựng cây nhị phân, về bản chất chúng ta đang rời rạc hóa một quá trình thời gian liên tục. Khoảng thời gian $[0, T]$ được chia thành $n$ bước nhỏ, mỗi bước có độ lớn $\delta t = T/n$.
Tốc độ hội tụ của cây nhị phân tiêu chuẩn được giả định tỷ lệ thuận với $1/n$, và có thể biểu diễn dưới dạng như sau:
\[C_N \approx C_{\infty} + \frac{A}{n} + o\left(\frac{1}{n}\right) \tag{9.1}\]Trong đó $C_\infty$ là giá quyền chọn thực, $A$ là hằng số phụ thuộc vào các tham số của quyền chọn, và $o(1/n)$ gọi là Little o dùng để chỉ một thành phần nhỏ hơn nhiều so với $1/n$ khi $n$ tiến tới vô cùng.
Về mặt học thuật, giả định hội tụ này đã được chấp nhận rộng rãi. Tiêu biểu như trong bài báo “The Rate of Convergence of the Binomial Tree Scheme”, John B. Walsh (2003) đã chứng minh chặt chẽ rằng sai số của mô hình bị giới hạn ở $\mathcal{O}(1/n)$, gọi là Big O. Lưu ý cần tránh nhầm lẫn giữa Little o thể hiện nhỏ hơn rất nhiều và Big O không bao giờ vượt quá so với $1/n$. Kết quả cụ thể của Walsh cho European Option có dạng như sau:
\[E_{\text{tot}}(f) = \left(A + B \theta(1-\theta)\right)\frac{1}{n} + \mathcal{O}(n^{-3/2}) \tag{9.2}\]trong đó $n$ là số bước, $A, B$ là các hằng số phụ thuộc vào tham số của quyền chọn, và $\theta$ là tham số của cây nhị phân. Dù không cần đi sâu vào chứng minh phức tạp, việc chấp nhận giả định trên là đủ để chúng ta hiểu được giới hạn thực tế của mô hình: để giảm một nửa sai số, bạn cần tăng gấp đôi số bước $n$ [3].
Bây giờ hãy nghĩ đến chi phí tính toán. Do độ phức tạp tính toán (time complexity) của thuật toán truy hồi ngược (backward induction) là $\mathcal{O}(n^2)$, để giảm sai số đi 10 lần, hệ thống của bạn phải xử lý khối lượng phép tính tăng lên gấp 100 lần. Đây là cái giá của việc tăng độ chính xác theo cách cơ bắp (brute force) nhất.
Vậy liệu có cách nào để triệt tiêu hiệu ứng răng cưa và tăng tốc độ hội tụ mà không phải trả giá quá lớn cho việc tính toán? Câu trả lời là có, và nó đến từ một ý tưởng toán học đơn giản đến bất ngờ, đó là Richardson Extrapolation.
2. Richardson Extrapolation: Giải pháp tăng tốc hội tụ
2.1. Ý tưởng: Ngoại suy điểm hội tụ
Nếu biết phần sai số lớn nhất tỷ lệ thuận với $1/n$ như giả định ở phần trước, ta không nên mù quáng tăng $n$ lên mức hàng nghìn để ép máy tính chạy quá mức. Thay vào đó, ta có thể chủ động giải hệ phương trình với hai cây nhị phân nhỏ (ví dụ $n$ và $2n$) để triệt tiêu hoàn toàn thành phần $\frac{A}{n}$ này. Đây chính là ý tưởng cốt lõi của Richardson Extrapolation, một kỹ thuật cổ điển trong toán học nhưng rất hiệu quả cho cây nhị phân.
Ta viết lại giả định hội tụ (9.1) bỏ qua số hạng rất nhỏ $o(1/n)$:
\[C_n \approx C_{\infty} + \frac{A}{n} \tag{9.3}\] \[C_{2n} \approx C_{\infty} + \frac{A}{2n} \tag{9.4}\]Lấy phương trình (9.4) nhân 2 rồi trừ đi phương trình (9.3), ta được:
\[2 C_{2n} - C_n \approx 2C_{\infty} + \frac{A}{n} - C_{\infty} - \frac{A}{n} = C_{\infty}\]Số hạng $\frac{A}{n}$ đã bị triệt tiêu, ta có:
\[C_{\text{extrapol}} = 2 C_{2n} - C_n \tag{9.5}\]Chỉ một công thức đơn giản nhưng có thể đem lại hiệu quả đáng kinh ngạc. Trong nhiều trường hợp thực tế, cây nhị phân 100 bước kết hợp với Richardson Extrapolation cho kết quả chính xác tương đương cây 1 000 bước thuần túy. Có nhiều cách chọn cặp bước nhảy $n$ cũng như công thức ngoại suy, xem thêm Phụ lục (A1).
Để hiểu tại sao kỹ thuật này lại kỳ diệu đến vậy, hãy nghĩ về phép nội suy tuyến tính đơn giản. Nếu bạn có hai điểm dữ liệu và biết rằng hàm số tiến về một điểm giới hạn, bạn có thể kéo dài đường thẳng qua hai điểm đó để ước tính điểm giới hạn. Đó chính xác là những gì Richardson Extrapolation đang làm, nhưng theo chiều nghịch: không phải nội suy (interpolate), mà là ngoại suy (extrapolate) về điểm $n \to \infty$.
2.2. Thử nghiệm trên cây nhị phân CRR
Richardson Extrapolation có thể áp dụng cho mọi cây nhị phân và hiệu quả của kỹ thuật này đến từ việc triệt tiêu số hạng $\frac{A}{n}$. Nếu sai số có cấu trúc khác xa giả định (9.1), thì việc áp dụng ngoại suy đôi khi không đem lại hiệu quả như mong muốn. Bài viết này chỉ thử nghiệm Richardson Extrapolation trên cây nhị phân tiêu chuẩn CRR.
CRR thường có hiện tượng răng cưa rõ rệt khi thay đổi $n$ từ chẵn sang lẻ. Ví dụ đơn giản cho quyền chọn ATM ($S = K$), khi $n$ chẵn, luôn có một nút rơi chính xác vào $K$, nhưng khi $n$ lẻ, $K$ lại nằm lơ lửng giữa hai nút lân cận $uS$ và $dS$. Điều này khiến cho sai số của CRR thực chất phức tạp hơn nhiều và có thể mô tả dưới dạng sau đây:
\[C_n^{CRR} \approx C_\infty + \frac{A}{n} + \text{Parity Oscillation} + \mathcal{O}\left(\frac{1}{n^2}\right) \tag{9.6}\]Trong đó, sai số dao động (parity oscillation) sinh ra do sự sai lệch vị trí hình học của giá thực hiện $K$ với các nút trên cây nhị phân khi $n$ thay đổi.
Khi áp dụng Richardson Extrapolation, số hạng tuyến tính $\frac{A}{n}$ bị triệt tiêu hoàn toàn, nhưng sai số dao động không bị triệt tiêu theo cách tuyến tính đó. Kết quả là, kỹ thuật ngoại suy trên CRR vẫn có thể để lại một phần nhiễu răng cưa dù sai số tổng thể đã nhỏ đi rất nhiều.
Bây giờ hãy cùng thử nghiệm nhận định trên. Trước hết ta viết hàm định giá quyền chọn binomial cho cả European Option và American Option theo mô hình nhị phân CRR. Hàm dựa trên thuật toán truy hồi ngược (backward induction) đã rất quen thuộc với bạn đọc.
Bạn có thể chạy thử thuật toán trên Google Colab.
![]()
import numpy as np
def binomial(S, K, T, r, sigma, n, option_type='call', exercise_type='european', model='CRR'):
dt = T / n
df = np.exp(-r * dt)
sign = 1 if option_type == 'call' else -1
if model == 'CRR':
u = np.exp(sigma * np.sqrt(dt))
d = 1 / u
q = (np.exp(r * dt) - d) / (u - d)
# 1. Initialize terminal payoffs
prices = S * (u**np.arange(n, -1, -1)) * (d**np.arange(n + 1))
values = np.maximum(sign * (prices - K), 0)
# 2. Backward induction
for i in range(n - 1, -1, -1):
values = df * (q * values[:-1] + (1 - q) * values[1:])
if exercise_type == 'american':
prices = prices[:-1] / u
exercise = np.maximum(sign * (prices - K), 0)
values = np.maximum(exercise, values)
return values[0]
Ta viết hàm định giá quyền chọn kết hợp thêm kỹ thuật Richardson Extrapolation. Dòng code price_extrapol = 2 * price_2n - price_n chính là công thức (9.5).
def richardson_extrapolation(S, K, T, r, sigma, n, option_type='call', exercise_type='european', model='CRR'):
price_n = binomial(S, K, T, r, sigma, n, option_type, exercise_type, model)
price_2n = binomial(S, K, T, r, sigma, 2 * n, option_type, exercise_type, model)
price_extrapol = 2 * price_2n - price_n
return price_extrapol, price_n, price_2n
Tiếp theo, ta định giá một American Put với cùng bộ tham số với ví dụ phía trên $S=100$, $K=100$, $T=1$, $r=5\%$, $\sigma=20\%$. Giá quyền chọn từ cây nhị phân 5000 bước reference được dùng làm giá trị chuẩn.
# Binomial vs. Richardson Extrapolation
S, K, T, r, sigma, = 100, 100, 1.0, 0.05, 0.20
reference = binomial(S, K, T, r, sigma, 5000, 'CRR', 'put', 'american')
Cuối cùng, ta vẽ đồ thị so sánh sai số so với giá trị reference khi dùng CRR và CRR+RE với số bước tăng dần từ 10 đến 200.
Nhìn vào biểu đồ trên, đường màu đỏ (CRR+RE) dao động dữ dội, thậm chí sai số còn lớn hơn đường màu xanh (CRR). Điều này cho thấy thực tế và lý thuyết có sự khác biệt. Nếu $C_n$ và $C_{2n}$ nằm ở hai phía của răng cưa, phép nhân 2 sẽ khuếch đại gấp đôi sai số thay vì triệt tiêu nó.
Một điểm cần chú ý là đường CRR+RE không dao động quanh 0 như đường CRR, mà lệch hẳn về phía dưới. Hơn nữa, hiện tượng này chỉ xảy ra khi $n$ lẻ ($n$ lẻ, $2n$ chẵn). Với cây CRR, có sự sai lệch lớn vị trí hình học của giá thực hiện $K$ so với các nút trên cây khi $n$ thay đổi từ chẵn sang lẻ. Áp dụng máy móc Richardson Extrapolation mà không quan tâm giá trị của $n$ có thể khiến kết quả tệ hơn (biểu đồ trên). Chỉ một thủ thuật nhỏ khi chọn cặp chẵn-chẵn ($n$ và $2n$) hoặc lẻ-lẻ ($n$ và $2n+1$), ta đã cải thiện đáng kể sai số cũng như tốc độ hội tụ của đường CRR+RE (biểu đồ dưới).

2.3. Thử nghiệm trên các vùng moneyness
Trong các tài liệu học thuật về định giá quyền chọn áp dụng Richardson Extrapolation, các tác giả thường chỉ kiểm chứng phương pháp này tại vùng ATM (at-the-money) tức là khi giá thực hiện xấp xỉ giá tài sản cơ sở. Đây là trường hợp mà sai số của cây nhị thức có xu hướng hội tụ tương đối ổn định, và Richardson Extrapolation phát huy tác dụng rõ rệt nhất.
Tuy nhiên, trong thực tế, các quyền chọn ITM (in-the-money) và đặc biệt là OTM (out-of-the-money) mới chiếm phần lớn khối lượng thị trường. Những trường hợp này có thể phức tạp hơn nhiều do cấu trúc sai số của cây nhị phân có thể khác xa so với giả định $\frac{A}{n}$. Trong phần tiếp theo, chúng ta sẽ so sánh hiệu năng của cây CRR kết hợp thêm Richardson Extrapolation trên cả ba vùng moneyness để thử nghiệm những giới hạn mà lý thuyết chưa nói rõ.
Ta tiếp tục định giá một American Put với cùng bộ tham số phía trên $S=100$, $T=1$, $r=5\%$, $\sigma=20\%$ nhưng với 3 mức moneyness $K=100$ (ATM), $K=80$ (OTM), $K=120$ (ITM). Hãy xem bảng so sánh dưới đây:
========================================================================
N CRR |Error| CRR+RE |Error| CRR+RE better?
========================================================================
ATM (K=100) | Reference = 6.090219
10 6.00426 0.08596 6.09035 0.00013 YES
20 6.04730 0.04292 6.09219 0.00197 YES
50 6.07373 0.01649 6.09098 0.00076 YES
100 6.08235 0.00786 6.09041 0.00019 YES
150 6.08504 0.00518 6.09040 0.00018 YES
200 6.08638 0.00384 6.09043 0.00021 YES
========================================================================
OTM (K=80) | Reference = 0.723621
10 0.75301 0.02939 0.73432 0.01070 YES
20 0.74367 0.02004 0.72489 0.00126 YES
50 0.71608 0.00754 0.73988 0.01626 NO
100 0.72798 0.00436 0.71757 0.00605 NO
150 0.72380 0.00018 0.72580 0.00218 NO
200 0.72277 0.00085 0.72345 0.00017 YES
========================================================================
ITM (K=120) | Reference = 20.136106
10 20.06354 0.07257 20.11779 0.01832 YES
20 20.09066 0.04545 20.16612 0.03001 YES
50 20.13765 0.00154 20.12290 0.01320 NO
100 20.13027 0.00583 20.14348 0.00738 NO
150 20.13509 0.00102 20.13161 0.00450 NO
200 20.13688 0.00077 20.13418 0.00192 NO
========================================================================
Để trực quan hơn, ta vẽ đồ thị sai số tuyệt đối trên thang logarithm giữa CRR và CRR+RE (Hình 3).
-
Tại ATM, CRR+RE hoạt động xuất sắc ở mọi mức $n$. Ngay từ $n = 10$, sai số CRR+RE đã chỉ còn 0.00013, nhỏ hơn sai số CRR khoảng 660 lần. Trên đồ thị, đường màu đỏ luôn nằm phía dưới đường màu xanh và gần như phẳng từ sớm tức đã hội tụ rất sớm.
-
Tại OTM, diễn biến trở nên phức tạp hơn đáng kể. Xét một cách tổng quát, CRR+RE cho sai số lớn hơn so với CRR. Quan sát biểu đồ, đường màu đỏ dao động mạnh: vọt cao hơn đường màu xanh tại các giá trị $n$ thấp, sau đó sụt giảm rồi lại tiếp tục tăng vọt một cách thiếu ổn định.
-
Tại ITM, nhìn chung hai phương pháp cho sai số khá gần nhau. Ở mức 50, 100, vùng $n$ vừa phải mà nhiều người thường chọn để cân bằng giữa tốc độ và độ chính xác, CRR+RE thua CRR một chút. Điểm quan trọng ở đây là CRR+RE thiếu ổn định, đường màu đỏ trồi sụt, không giống như đường màu xanh thể hiện sự hội tụ rõ ràng.

Kết quả trên cho thấy cần thận trọng khi áp dụng Richardson Extrapolation, đặc biệt ở vùng ITM/OTM. Hiệu quả của nó phụ thuộc mạnh vào vùng moneyness, cấu trúc của cây nhị phân, và cả cách chọn $n$. Đây là khoảng trống mà các tài liệu học thuật thường im lặng, người thực hành cần tự kiểm chứng trước khi triển khai.
3. Black-Scholes Smoothing: Kỹ thuật làm mượt và ổn định sai số
3.1. Nguồn gốc hiệu ứng răng cưa
Richardson Extrapolation, kết hợp hai cây nhị phân để triệt tiêu số hạng sai số, là cách tiếp cận bên ngoài, sửa chữa sau khi cây đã chạy xong. Nhưng có một hướng tiếp cận khác vào bên trong cây, can thiệp ngay tại điểm mà sai số được sinh ra, đó là BBS (Black-Scholes Smoothing).
Để hiểu ý tưởng của BBS, cần hiểu rõ nguốn gốc của hiệu ứng răng cưa. Hãy tưởng tượng cây nhị phân như một dây chuyền sản xuất chạy ngược. Sản phẩm đầu ra, giá quyền chọn tại gốc cây, phụ thuộc hoàn toàn vào nguyên liệu đầu vào ở cuối dây chuyền, tức payoff tại các nút. Với quyền chọn mua là $\max(S_j − K, 0)$, tức nếu $S_T>K$ quyền chọn sẽ có giá trị còn ngược lại giá trị bằng 0. Hàm payoff này không liên tục, mà có một điểm gẫy tại đúng $S = K$.
Khi một nút rơi vào vùng lân cận $K$ và $n$ thay đổi khiến nút đó nhảy từ bên trái sang bên phải hoặc ngược lại, payoff của nút đó không thay đổi tuyến tính mà thay đổi theo kiểu nhị phân: từ một giá trị dương thành 0, hoặc ngược lại. Chính sai số theo kiểu nhị phân này lan truyền ngược lên toàn bộ cây qua truy hồi ngược và khuếch đại sai số dao động (parity oscillation).
3.2. Ý tưởng: Thay payoff rời rạc bằng giá trị Black-Scholes
Broadie-Detemple (1996) [5] đề xuất một cách khắc phục như sau: thay vì dùng payoff rời rạc $\max(S_j - K, 0)$, hãy thay nó bằng giá Black-Scholes của European Option tương ứng tại một bước trước khi đáo hạn.
Ý tưởng cụ thể như sau. Thay vì chạy cây $n$ bước và lấy payoff tại nút $n$ làm điểm khởi đầu:
\[C_j^{(n)} = \max(S_j^{(n)} - K,\ 0) \tag{9.7}\]BBS chạy cây $n-1$ bước, rồi tại bước cuối cùng, tức tại thời điểm $t = T - \delta t$, tính giá trị bằng công thức Black-Scholes với thời gian còn lại $\delta t = T/n$:
\[C_j^{(n-1)} = \text{BS}_{\text{call}} \left(S_j^{(n-1)}, K, \delta t, r, \sigma \right) \tag{9.8}\]Tại sao điều này lại giải quyết được hiện tượng răng cưa? Vì công thức Black-Scholes là một hàm trơn hoàn toàn (infinitely differentiable) theo $S$. Thay vì payoff với những cú nhảy nhị phân cứng nhắc quanh vùng giá thực hiện, BBS giúp khởi đầu bằng giá trị mượt mà liên tục biết nội suy qua thay vì nhảy qua nó. Hiệu ứng răng cưa không biến mất hoàn toàn vì cấu trúc lưới vẫn còn đó, nhưng sai số nguy hiểm nhất đã bị vô hiệu hóa.
Một cách hình dung khác là Black-Scholes đóng vai trò như một bộ lọc cho tầng cuối cùng của cây. Nó giữ lại thông tin kinh tế (giá trị kỳ vọng của payoff) nhưng loại bỏ nhiễu số học (sự phân loại nhị phân cứng nhắc quanh giá thực hiện).
3.3. Thử nghiệm Black-Scholes Smoothing
Thực thi BBS (Black-Scholes Smoothing) rất đơn giản. Ta tạo một hàm mới binomial_bss gần như giống hết với hàm binomial phía trên, chỉ thay đổi một chút tại bước khởi tạo giá trị tại tầng cuối của cây nhị phân.
Thay vì dùng payoff values = np.maximum(sign * (prices - K), 0) tại bước n, ta dùng công thức Black Scholes values = np.array([black_scholes(s, K, dt, r, sigma, option_type) for s in prices]) tại bước n_prev = n - 1.
def binomial_bss(S, K, T, r, sigma, n, option_type='call', exercise_type='european', model='CRR'):
...
# 1. Initialize terminal payoffs at n-1
n_prev = n - 1
prices = S * (u**np.arange(n_prev, -1, -1)) * (d**np.arange(n_prev + 1))
values = np.array([black_scholes(s, K, dt, r, sigma, option_type) for s in prices])
# Check Early Exercise at n-1
if exercise_type == 'american':
values = np.maximum(values, np.maximum(sign * (prices - K), 0))
# 2. Backward induction
for i in range(n_prev - 1, -1, -1):
...
Nếu xét độ phức tạp tính toán (time complexity), BBS thêm một bước tính Black Scholes cùng n-1 bước truy hồi thay vì n bước như cây tiêu chuẩn. Như vậy, tổng chi phí tính toán trong hai trường hợp có thể coi là bằng nhau, nhưng điểm khởi đầu đã được làm mượt đáng kể.
BBS hoạt động tốt nhất với European Option hay phần european-like của quyền chọn. Với American Option, bước làm mượt chỉ xử lý được phần sai số ở tại tầng cuối, mà không giải quyết được sai số liên quan đến đường biên thực hiện tối ưu nằm ở các tầng giữa của cây. BBS không được kỳ vọng sẽ có nhiều hiệu quả cho trường hợp deep in-the-money.
Ta vẽ đồ thị so sánh sai số tuyệt đối trên thang logarithm giữa các phương pháp CRR, CRR+RE, CRR+BSS, CRR+RE+BSS cho cả European Option (phía trên) và American Option (phía dưới).


-
CRR+RE chỉ hiệu quả và ổn định tại ATM. Đường màu đỏ nằm nhất quán dưới đường màu xanh, hội tụ nhanh hơn và sớm đạt trạng thái phẳng ở mức sai số rất thấp.
-
CRR+BSS là phương pháp có hiệu quả vượt trội trên cả ba vùng ATM, ITM, OTM. Đường màu xanh lá hội tụ chậm hơn CRR+RE tại ATM, nhưng luôn ổn định, đơn điệu, và không có dao động ngay cả khi ở $n$ nhỏ. Tuy nhiên đúng như lý thuyết, CRR+BSS thất bại tại American Option ITM. Lúc này giá trị thực hiện sớm chiếm ưu thế và xuất hiện nhiều ở các tầng giữa của cây, công thức Black-Scholes áp dụng tại tầng cuối không có nhiều ý nghĩa. Đây là giới hạn của CRR+BSS mà người thực hành cần biết.
-
Một điểm thú vị là khi kết hợp cả hai phương pháp, CRR+BSS+RE (đường màu tím) còn cho kết quả tốt hơn cả CRR+BSS (đường màu xanh lá) trong mọi trường hợp.
Mục tiêu quan trọng nhất của BBS là làm mịn dao động, không phải tối ưu tốc độ hội tụ. Để kiểm tra tính chất này của BSS, ta vẽ đồ thị sai số tương đối cho từng bước $n$ liên tiếp từ 10 đến 150 như Hình 2, để thể hiện được hiệu ứng răng cưa.

Nhìn vào cả ba trường hợp, đặc biệt là trường hợp ITM được cho là thách thức nhất với BSS, đường xanh lá hội tụ cực kỳ ổn định gần như không có dao động. Đây chính xác là lý do vì sao phương pháp này có tên gọi là smoothing. Tính chất này có giá trị hơn nhiều tốc độ hội tụ thuần túy, hệ thống cần kết quả nhất quán và ít nhạy cảm với lựa chọn $n$ hơn là cần $n$ tối ưu.
4. Leisen-Reimer (1996): Cấu trúc cây nhị phân tối ưu
Richardson Extrapolation hay Black-Scholes Smoothing là kỹ thuật sửa chữa sai số, và có thể áp dụng trên mọi cây nhị phân từ Cox-Ross-Rubinstein (1979), Jarrow-Rudd (1983), đến Chance (2007). Nhưng thay vì cố gắng sửa sai, ngay từ đầu có thể xây dựng cây nhị phân tối ưu không? Đây chính là câu hỏi của Leisen-Reimer (1996).
4.1. Ý tưởng: Khớp trực tiếp giá quyền chọn
Trong các cây nhị phân thông thường, bài toán thường bắt đầu bằng việc khớp mô men giá tài sản $S$ để đảm bảo phân phối nhị thức hội tụ về log-normal. Tuy nhiên, việc này không kiểm soát được tốc độ hội tụ của giá quyền chọn. Hai phân phối có thể có cùng kỳ vọng và phương sai, nhưng khác nhau hoàn toàn ở phần đuôi quanh $K$, nơi ảnh hưởng lớn tới giá quyền chọn. Triết lý ở đây là thiết kế $u, d, q$ sao cho phân phối $S$ đúng, và hy vọng giá quyền chọn sẽ đúng theo.
Ngược lại, LR khớp trực tiếp giá quyền chọn từ mô hình nhị phân vào công thức Black-Scholes, bằng cách ép hai hàm phân phối nhị thức hội tụ về hai số hạng của Black-Scholes.
\[\begin{aligned} C_{binomial} &= S B(j, n, q') - K e^{-rT} B(j, n, q) \\ C_{BS} &= S N(d_1) - K e^{-rT} N(d_2) \end{aligned} \tag{9.9}\]Leisen-Reimer chọn $q$ và $q’$ sao cho đồng thời:
\[B(a, n, q') = N(d_1) \quad \text{and} \quad B(a, n, q) = N(d_2) \tag{9.10}\]Với $n$ hữu hạn, không thể tái tạo chính xác $N(d_1)$, $N(d_2)$ vì đây là phân phối liên tục, nhưng có thể tái tạo xấp xỉ bằng cách dùng hàm nghịch đảo của CDF chuẩn tắc, gọi là Peizer-Pratt Inversion. Như vậy, ý tưởng của LR là ép giá đúng ngay từ đầu, rồi mới thiết kế ngược ra $u, d, q$.
Hình dung một cách đơn giản, CRR tối ưu hóa đầu vào của cây (khớp phân phối giá tài sản), còn LR tối ưu hóa đầu ra (khớp giá quyền chọn). Đây là lý do tại sao LR vượt trội về tốc độ hội tụ cũng như sai số, nó nhắm thẳng vào mục tiêu cuối cùng thay vì đi đường vòng qua phân phối trung gian. Tuy nhiên, đây cũng là điểm giới hạn của LR, vì $q, q’$ được thiết kế dựa trên $d_1, d_2$ của một giá thực hiện cụ thể $K$, nếu muốn tính giá quyền chọn với $K$ khác thì phải xây dựng lại toàn bộ cây, khác với cây nhị phân thông thường nơi một cây dùng được cho mọi $K$.
4.2. Hàm xấp xỉ Peizer-Pratt và công thức Leisen-Reimer
Để căn chỉnh cây với $K$, LR cần một hàm xấp xỉ nghịch đảo cho phân phối chuẩn tắc $N(x)$ mà hoạt động tốt ở dạng rời rạc. Trong bài báo gốc, họ trình bày cả ba phương pháp nghịch đảo Camp-Paulson, Peizer-Pratt 1 và Peizer-Pratt 2, xem thêm Phụ lục (A2). Tuy nhiên ở đây ta chỉ sử dụng công thức Peizer-Pratt 2 [7], một xấp xỉ hội tụ nhanh và chính xác hơn các xấp xỉ thông thường khi số bước $n$ tăng:
\[h(z, n) = \frac{1}{2} + \frac{\text{sign}(z)}{2}\sqrt{1 - \exp\!\left(-\left(\frac{z}{n+\frac{1}{3}+\frac{0.1}{n+1}}\right)^{\!2}\!\left(n + \frac{1}{6}\right)\right)} \tag{9.11}\]Với $d_1$ và $d_2$ từ Black-Scholes, các tham số LR được xác định như sau:
\[d_1 = \frac{1}{\sigma \sqrt{T-t}} \left[ \ln\left(\frac{S_t}{K}\right) + \left(r + \frac{\sigma^2}{2}\right)(T-t) \right] \\ d_2 = d_1 - \sigma \sqrt{T-t} \tag{9.12}\] \[q' = h(d_1, n), \quad q = h(d_2, n) \tag{9.13}\] \[u = \frac{e^{r \delta t} q'}{q}, \quad d = \frac{e^{r \delta t} - q u}{1 - q} \tag{9.14}\]Trong đó $q$ là xác suất trung hòa rủi ro và $q’$ là một xác suất phụ dùng để xây dựng $u$.
Một điều quan trọng cần lưu ý trong cây nhị phân LR, $n$ phải là số lẻ để đảm bảo có một nút trung tâm duy nhất tại điểm ATM (at-the-money), giúp cả hai nhánh đều phân phối đối xứng quanh $K$.
4.3. Thử nghiệm Leisen-Reimer
Để xây dựng cây nhị phân LR, ta thêm một đoạn mã elif model == 'LR': vào hàm binomial phía trên. Hàm def peizer_pratt(z, n) được xây dựng theo xấp xỉ Peizer-Pratt (9.11), u và d được tính theo công thức (9.14).
def binomial(S, K, T, r, sigma, n, option_type='call', exercise_type='european', model='CRR'):
if model == 'LR' and n % 2 == 0: n += 1
...
if model == 'CRR':
...
elif model == 'LR':
def peizer_pratt(z, n):
inner = -((z / (n + 1/3 + 0.1/(n+1)))**2) * (n + 1/6)
return 0.5 + np.sign(z) * 0.5 * np.sqrt(1 - np.exp(inner))
d1 = (np.log(S / K) + (r + 0.5 * sigma**2) * T) / (sigma * np.sqrt(T))
d2 = d1 - sigma * np.sqrt(T)
q_prime = peizer_pratt(d1, n)
q = peizer_pratt(d2, n)
u = np.exp(r * dt) * q_prime / q
d = (np.exp(r * dt) - q * u) / (1 - q)
...
Để trực quan nhất, ta chỉ vẽ đồ thị hội tụ của LR và CRR+BSS, là phương pháp rất tốt từ phần trước.
-
Đối với European Option: LR (đường màu cam) cho thấy ưu thế tuyệt đối so với CRR+BSS (đường màu xanh lá) trong mọi trường hợp. LR hội tụ về giá Black-Scholes cực kỳ nhanh, ngay cả với số bước nhảy $n$ rất nhỏ. Sai số gần như bằng 0 ngay từ đầu, trong khi CRR+BSS cần nhiều bước nhảy hơn mới đạt được độ chính xác tương đương. Đường hội tụ của LR cũng rất ổn định, chứng tỏ cây LR đã triệt tiêu hiệu quả hiện tượng dao động đặc trưng của các mô hình nhị phân truyền thống.
-
Đối với American Option: LR không còn chiếm ưu thế. Có thể thấy đường màu cam và đường màu xanh bám sát nhau, thậm chí trong trường hợp OTM và ITM, CRR+BSS còn cho sai số thấp hơn ở các giá trị $n$ thấp. Điều này xác nhận thế mạnh căn chỉnh $K$ của LR phát huy tốt nhất khi chỉ tính toán tại một thời điểm đáo hạn duy nhất.


Không có một phương pháp nào là tốt nhất cho mọi tình huống. Trong thực tế, các hệ thống định giá thường kết hợp nhiều kỹ thuật và kiểm tra chéo thay vì tin tưởng một phương pháp duy nhất.
5. Tóm tắt và thảo luận
Trong bài viết này, chúng ta đã cùng điểm qua một số hạn chế cũng như các phương pháp cải thiện khi đưa cây nhị phân vào sử dụng thực tế.
-
Từ các bài nghiên cứu học thuật, John B. Walsh (2003), chúng ta học được rằng cây nhị phân hội tụ với tốc độ $\mathcal{O}(1/n)$, chậm và rất tốn kém. Hiệu ứng răng cưa là bình thường đối với một cây nhị phân tiêu chuẩn, không phải lỗi.
-
Từ Richardson Extrapolation (RE), chúng ta học được rằng để tăng độ chính xác đôi khi chỉ cần sử dụng một kỹ thuật đơn giản như ngoại suy từ hai kết quả. Công thức $2 C_{2n} - C_n$ đơn giản đến bất ngờ nhưng hiệu quả đáng kinh ngạc.
-
Từ Black-Scholes Smoothing (BSS), chúng ta nhận ra rằng việc xử lý các nút ngay trước thời điểm đáo hạn là chìa khóa để ổn định mô hình. Bằng cách thay thế giá trị payoff rời rạc tại bước trước khi đáo hạn bằng giá Black-Scholes, BSS đã làm mượt và triệt tiêu hiệu ứng răng cưa.
-
Từ Leisen-Reimer (1996), chúng ta học được rằng có một cách thanh lịch hơn *RE, BSS: thay vì sửa sai số sau khi tính toán, hãy thiết kế cây nhị phân để sai số gần như không tồn tại từ đầu. LR căn chỉnh nút cây với giá thực hiện, loại bỏ răng cưa tại gốc, và trong nhiều thử nghiệm vượt trội cả RE và BSS.
-
Thực hành Python

Appendix
A1. Cách chọn $n$ khác cho Richardson Extrapolation, Joshi, M. S. (2007)
Trong quá trình áp dụng Richardson Extrapolation, việc lựa chọn cặp bước nhảy cũng đóng vai trò quan trọng trong việc triệt tiêu các thành phần sai số bậc thấp.
Lựa chọn đơn giản nhất là dùng cặp $(n, 2n)$ và công thức $Y_n = 2X_{2n} - X_n$ như đã trình bày ở trên. Cặp này giúp triệt tiêu số hạng $E/n$, nhưng đôi khi gây ra vấn đề là khi $n$ lẻ, $2n$ chẵn. Joshi đề xuất cặp $(n, 2n+1)$ và công thức tính $Y_n = A_n X_n + B_n X_{2n+1}$ [4].
Giả sử giá quyền chọn sau $n$ bước có dạng:
\[X_n = \text{TruePrice} + \frac{E}{n} + o(1/n) \tag{9.A1.1}\]Lấy tổ hợp tuyến tính hai ước lượng tại $n$ và $2n+1$:
\[Y_n = A_n X_n + B_n X_{2n+1} \tag{9.A1.2}\]Với hai điều kiện:
\[A_n + B_n = 1 \\ \frac{A_n}{n} + \frac{B_n}{2n+1} = 0 \tag{9.A1.3}\]Giải hệ phương trình trên, ta có:
\[A_n = 1 - \left(1 - \frac{n}{2n+1}\right)^{-1}, \qquad B_n = \left(1 - \frac{n}{2n+1}\right)^{-1} \tag{9.A1.4}\]Kết quả là số hạng sai số bậc $1/n$ bị triệt tiêu hoàn toàn, ta có: $Y_n = \text{TruePrice} + o(1/n)$.
A2. Hàm xấp xỉ nghịch đảo cho phân phối nhị thức, Leisen-Reimer (1996)
Bài toán chung: cho số bước $n$ và giá trị $z$ từ phân phối chuẩn (thường là $d_1$ hoặc $d_2$ của Black-Scholes), tìm $q \in (0,1)$ sao cho:
\[B\left(j, n, q\right) = N(z)\]Leisen-Reimer trình bày ba phương pháp dưới đây cho hàm xấp xỉ nghịch đảo [6].
Camp-Paulson Inversion (CP)
$h(z, n) = \left( \frac{b}{a} \right)^2 \left( \frac{[9a - 1][9b - 1] + 3z\left[a(9b - 1)^2 + b(9a - 1)^2 - 9abz^2\right]^{\frac{1}{2}}}{[9b - 1]^2 - 9bz^2} \right)^{\frac{1}{3}} \tag{9.A2.1}$
Trong đó: $j = \frac{n-1}{2}$, $a = n - j$, $b = j + 1$
Peizer-Pratt Inversion (PP1)
\[h(z, n) = \frac{1}{2} + \frac{\text{sign}(z)}{2} \sqrt{1 - \exp\!\left(-\left(\frac{z}{n + \tfrac{1}{3}}\right)^{\!2}\!\left(n + \tfrac{1}{6}\right)\right)} \tag{9.A2.2}\]Trong đó: $n = 2j + 1$
Peizer-Pratt Inversion (PP2)
\[h(z, n) = \frac{1}{2} + \frac{\text{sign}(z)}{2} \sqrt{1 - \exp\!\left(-\left(\frac{z}{n + \tfrac{1}{3} + \tfrac{0.1}{n+1}}\right)^{\!2}\!\left(n + \tfrac{1}{6}\right)\right)} \tag{9.A2.3}\]Trong đó: $n = 2j + 1$
Phương pháp PP2 chính xác hơn một chút so với PP1, đặc biệt với $n$ nhỏ. Điểm khác biệt duy nhất nằm ở phần dư $0.1/(n+1)$ dưới mẫu số. Đây cũng là phương pháp Leisen-Reimer sử dụng.
Trong bài báo gốc [6], Leisen-Reimer thử nghiệm cả ba phương pháp trên, ghi nhận lại RMS error (Root Mean Squared error) và so sánh với giá hội tụ chuẩn như hình dưới đây. Kết quả cho thấy cả ba phương pháp đều cho kết quả tốt hơn cây nhị phân thông thường (càng lệch trái càng tốt). PP1 và PP2 cho RMS tương đương, CP cho RMS cao hơn một chút.
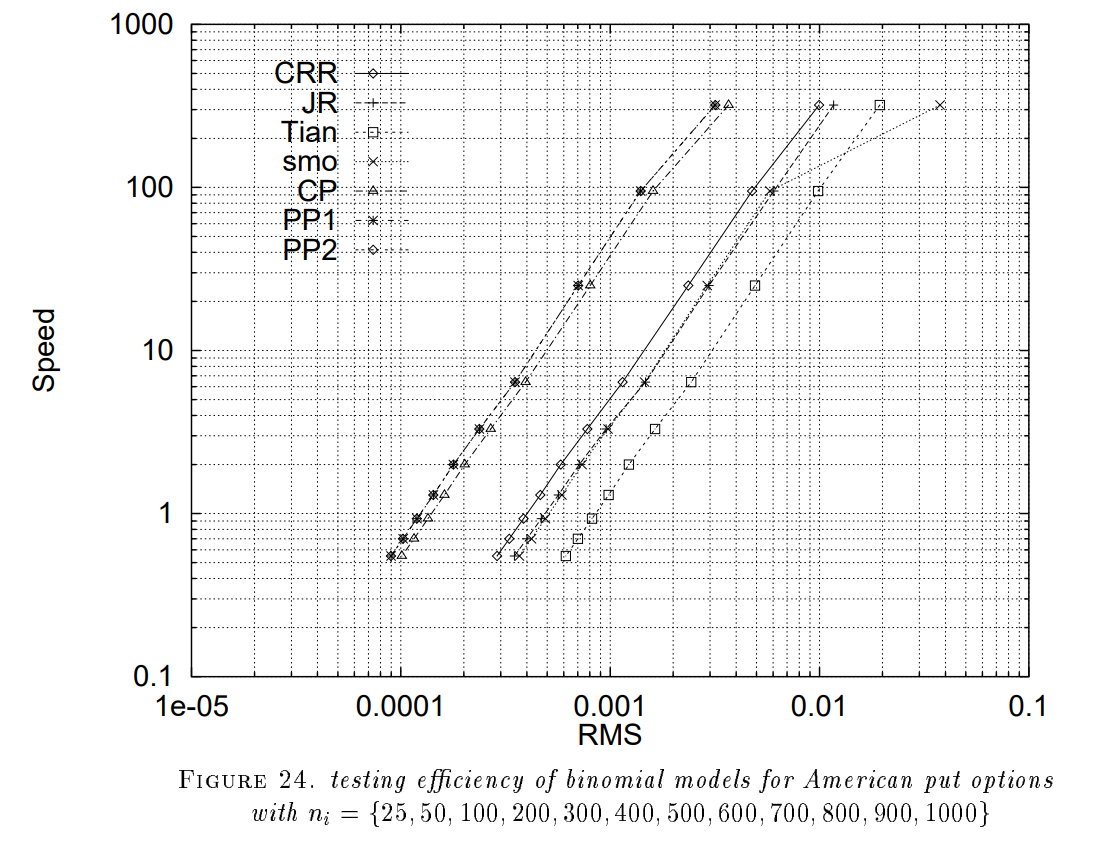
- Cox, J. C., Ross, S. A., & Rubinstein, M. (1979). Option pricing: A simplified approach. Journal of Financial Economics, 7(3), 229–263.
- Jarrow, R. A., & Rudd, A. (1983). Option Pricing. Dow Jones-Irwin.
- Walsh, J. B. (2003). The Rate of Convergence of the Binomial Tree Scheme. Finance and Stochastics, 7(3), 337–361.
- Joshi, M. S. (2007). The Convergence of Binomial Trees for Pricing the American Put. Available at SSRN 1030143.
- Broadie, M., & Detemple, J. (1996). American Option Valuation: New Bounds, Approximations, and a Comparison of Existing Methods. The Review of Financial Studies, 9(4), 1211–1250.
- Leisen, D. P. J., & Reimer, M. (1996). Binomial models for option valuation: examining and improving convergence. Applied Mathematical Finance, 3(4), 319–346.
- Peizer, D. B., & Pratt, J. W. (1968). A Normal Approximation for Binomial, F, Beta, and other Common, Related Tail Probabilities. Journal of the American Statistical Association, 63(324), 1416–1456.
- Haug, E. G. (2007). The Complete Guide to Option Pricing Formulas (2nd ed.). McGraw-Hill.
- Hull, J. C. (2021). Options, Futures, and Other Derivatives (11th ed.). Pearson.